Over the last few blog posts, I’ve discussed some of the basics of what machine learning is and why it’s important:
– Why machine learning will reshape software engineering
– What is the core task of machine learning
– How to get started in machine learning in R
Throughout those posts, I’ve been using the following definition of machine learning: creating computational systems that learn from data in order to make predictions and inferences.
However, machine learning isn’t the only subject in which we use data for prediction and inference. Anyone who’s taken an introductory statistics class has heard a similar definition about statistics itself. And if you talk to someone who works in data-mining, you’ll hear the same thing: data mining is about using data to make predictions and draw conclusions from data.
This raises the question: what is the difference between machine learning, statistics, and data mining?
The long answer has a bit of nuance (which we’ll discuss soon), but the short answer answer is very simple: machine learning, statistical learning, and data mining are almost exactly the same.
An expert opinion: there is no difference
Larry Wasserman wrote a blog post about this a few years ago. If you’re not familiar with him, Wasserman is a professor in both the Department of Statistics and in the Machine Learning Department at Carnegie Mellon, one of the premier universities for stats and ML. Moreover, I’ll point out that Carnegie Mellon is one of the few universities that has a department devoted exclusively to machine learning. Given that Wasserman is officially a professor in ML and statistics at one of the best technical universities in the world, I’d say that he’s uniquely positioned to answer this question.
(As an aside: Wasserman also wrote the confidently titled book, All of Statistics. It’s not for a beginner, but for those of you with at least an intermediate background in math, All of Statistics will be excellent preparation for ML.)
According to Wasserman, what’s the difference?
“The short answer is: None. They are … concerned with the same question: how do we learn from data?”
To be clear, Wasserman was specifically addressing the difference between “machine learning” and “statistics” (he didn’t mention data mining). However, I’ll add that his answer applies equally well to “data mining”.
So to echo what Wasserman wrote, and re-state the point: machine learning, statistics, and data mining are mostly the same.
Having said that, Wasserman notes that if you look at some of the details, there is a “more nuanced” answer that reveals minor differences.
With that in mind, let’s review the major similarities as well as the differences, both to prove the point that they really are extremely similar, and also to give you the more nuanced view.
The core similarities between ML, stats, and data mining
First, let’s examine the what makes machine learning, statistics, and data mining fundamentally similar.
Nearly identical subject-matter and toolkits
The primary reason that these three subjects are effectively the same is that they cover almost exactly the same material and use almost exactly the same techniques.
Let me give you an example. If you examine the table of contents of An Introduction to Statistical Learning, you’ll find chapters on regression, classification, resampling, and non-linear methods. If you examine the contents a bit more closely, you’ll see sections concerning linear regression, logistic regression, the bias-variance tradeoff, neural networks, and support vector machines.
Now take a look a the syllabus for Andrew Ng’s machine learning course on Coursera, and you’ll see all of the topics I just listed. The material covered in Ng’s machine learning course is almost exactly the same as the material covered in ISL; said differently, the material covered by the “statistical learning” experts is the same as that covered by the “machine learning” experts. With only minor exceptions, the material is exactly the same.
If you perform the same exercise and look at the table of contents for the book Data Mining by Witten, Frank, and Hall, you’ll find almost exactly the same material. Again: regression, classification, neural networks, etc.
So to summarize, the material covered in machine learning, statistics (and statistical learning in particular), and data mining are so similar that they’re nearly identical.
The three cultures: why there are three identical subjects with different names
So what gives? They’re nearly identical! Why are there three different subjects that cover the exact same material (much to the confusion of data science newbies)?
The best answer here is that even though they use the same methods, they evolved as different cultures, so they have different histories, nomenclature, notation, and philosophical perspectives.
Let me give you an analogy: “machine learning” and “statistics” are like identical twins (triplets, if you want to include “data mining” in the analogy). They are quite nearly identical. And in fact, at a deep level, they are identical: they “share the same DNA” as it were.
However, even though identical twins are identical in some sense, they might still dress differently and hang out with different people.
To relate this to the topic of ML, statistics, and data mining, what I mean by “dressed differently” is that they use different words and terms, and have different notation. Much like human twins that have different groups of friends, people in ML, stats, and data mining also have different and separate social groups: they exist in different academic departments (in most universities), typically publish in different journals, and have different conferences and events.
The core differences between ML, stats, and data mining
Let’s examine these differences a little more closely.
They emphasize different things
Perhaps the biggest difference between these three fields is their emphasis. Although they use almost the exact same methods, they tend to emphasize different things. A different way of saying this, is that although they use almost exactly the same methods, tools, and techniques, these three fields have philosophical differences concerning how and when those methods should be applied.
In his blog post, Wasserman mentioned these different emphases, noting that “statistics emphasizes formal statistical inference (confidence intervals, hypothesis tests, optimal estimators) in low dimensional problems.” (To be clear, in this quote, Wasserman seems to be talking about statistics broadly, and not statistical learning in particular.)
Wasserman went on to note that machine learning is more focused on making accurate predictions – a sentiment echoed by Professor Andrew Gelman of Columbia University. Because of this purported emphasis on prediction above all, some people characterize ML as being less “strict” about testing assumptions; that in ML, making good predictions trumps more formal considerations like testing assumptions, etc.
Machine learning is focused on software and systems
Actually, I’ll go a step further and state that machine learning isn’t just more focused on making predictions, but is more focused on building software systems that make predictions. That is, among ML practitioners (as opposed to statisticians), there is a much stronger emphasis on software engineering. This makes sense considering the historical growth of machine learning as a sub-discipline of computer science; historically, machine learning developed because computer scientists needed a way to create computer programs that learn from data.
This greater emphasis on systems (i.e., computer programs that learn from data) leads some people to argue that ML is more of an “engineering discipline” whereas statistics is more of a “mathematical” discipline. Again though, I’ll repeat my caveat that these are very broad generalizations.
The purpose of data mining is finding patterns in databases
How about data mining?
As I already noted, the tools that data miners use are almost exactly the same as the tools used by statisticians and machine learning experts. The major difference is how and why these tools are used. So how do data miners apply these techniques, and to what end?
Here’s its quite helpful to look at the name “data mining.”
As the name implies, “data mining” is akin to mining. In a mining operation – for example a gold mining operation – large piles of dirt and material are extracted from the mine and then the miners sift through the dirt to find nuggets of gold. Here you can think of a data warehouse as the mine: it contains mostly useless data. This useless data is like the “dirt and rubble” in a mine. Then after being extracted from the database, this “useless” data needs to be “mined” for valuable insight.
Sometimes, finding these insights requires simple exploratory data analysis. Sometimes it requires more formal statistical techniques like hypothesis testing. And sometimes it requires building models – basically the same types of models used in machine learning and statistical learning.
So again, we find that the tools are almost identical, but the purpose is slightly different: finding valuable insights in large databases.
To summarize: that although ML, stats, and data mining use the same methods, they have slightly different philosophies about how, when, and why to apply those methods.
They use different words and terminology
Not only do they have slightly different emphases and purposes, they also use different terminology.
Professor Rob Tibshirani – one of the authors of the excellent book An Introduction to Statistical Learning – created a glossary comparing several major terms in machine learning vs statistics.
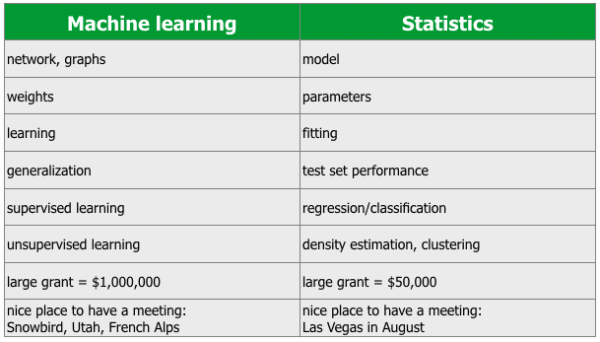
While a few of these comparisons are a bit tongue-in-cheek, the list is instructive. Most specifically, the chart drives home the point I’ve been making in this post: machine learning and statistics are quite nearly identical. They are so similar that they discuss almost all of the same topics, methods, and concepts, but just have different names for many of them.
Having said that, I want to add that frequently these terms are used interchangeably by people in stats and machine learning (as well as data mining).
For example, if you examine Andrew Ng’s machine learning course, you’ll find that he frequently uses the term “parameter” instead of “weight”. Although most people would consider Ng a member of the “machine learning culture”, but he readily uses the terms attributed to the “statistical learning culture.” So, it appears that even though there are slight cultural differences, even those differences are insubstantial; members of the “different cultures”, basically use terminology interchangeably.
ML, stats, and data mining tend to favor different tools
Next, let’s talk about tools. There are some very rough generalizations we can make about tool choices between statisticians, data miners, and machine learning practitioners (but as I’ve pointed out several times, these are sort of hasty generalizations).
In the machine learning camp, you’re more likely to see Python and Matlab. If you do a quick review of the major courses and texts on machine learning, many of them use one of these two languages. For example, Andrew Ng’s course teaches ML labs in Matlab, as do several other excellent books by authors such as Barber or Murphy.
Outside of academia, and particularly in San Francisco/Silicon Valley, you’ll often see Python as a primary ML tool of choice.
On the statistics side, you’re much more likely to see R. You’re very likely to see R used as the primary programming language for probability and statistics classes at colleges and universities. Also, several of the best books on probability, statistics, Bayesian statistics, and statistical learning use R for their exercises and labs.
I’ll repeat though that these are very hasty generalizations. You’ll see statisticians using Matlab, and you’ll certainly see machine learning practitioners using R. Moreover, as ML, stats, and data mining practitioners begin to cooperate and these fields begin to converge, you’re seeing people learn several tools. Many of the best people in stats and ML know python and R, as well as other tools.
And of course, the list certainly isn’t limited to Python, R, and Matlab. In both academia and industry, you’ll find statisticians, ML experts, and data miners using a broad array of other technologies like SAS, SPSS, c++, Java and others.
So while I’ll suggest that Python and Matlab are more popular among the ML crowd and that R is more popular among statisticians, again, this is really just a quick-and-dirty generalization.
ML and data mining typically work on “bigger” data than statistics
Finally, let’s talk briefly about the size and scale of the problems these different groups work on.
The general consensus among several of the prominent professors mentioned above is that machine learning tends to emphasize “larger scale” problems than statistics.
Wasserman noted in his blog post that in contrast to statistics, machine learning emphasizes “high dimension” prediction problems (which presumably means that machine learning emphasizes problems with a larger number of predictor variables).
Andrew Gelman – who is also a very well respected professor of statistics – similarly implies that statistics emphasizes smaller scale problems: “My impression is that computer scientists work on more complicated problems and bigger datasets, in general, than statisticians do.”
And finally, data mining also emphasizes large scale data. While I won’t offer any quotes here, I can say from personal experience that people who identify as “data miners” commonly work with databases that have millions, even hundreds of millions or billions of observations (although, it’s quite common to subset these large datasets down, to take samples, etc).
Again: there are far more similarities than differences
It should seem clear by now that machine learning, statistics, and data mining are all fundamentally similar. And to the extent that they have differences, those differences are – in the words of Revolution Analytics’ David Smith – more superficial than substantive.
Moreover, even though there are differences – particularly philosophical differences – you need to realize that these fields are beginning to converge. As Wasserman noted in his blog article, it’s clear that members of these communities are beginning to communicate with one another, and the lines between these fields are becoming increasingly blurred. So even if we can identify some differences, those differences may become much less pronounced over time.
What this means for you, if you’re getting started with data science, is that you can safely treat machine learning, statistics, and data mining as “the same.” Learn the “surface level” differences so you can communicate with people from the “different cultures,” but ultimately, treat machine learning, statistics, and data mining each as subjects that you can learn from as you work to master data science.
Nice article, Josh! I didn’t realize that ML, stats, and DM were very similar.
Nice article and much needed! as a chemical engineer who knows R, matlab and statistics, this always confused me. so to make progress as a data scientist, statisticians need to brush up on programming, programmers (ML folks) need to learn statistics and big data analysis needs additional tools along with stats knowledge and programming.
As I already noted, the tools that data miners use are almost exactly the same as the tools used by statisticians and machine learning experts. The major difference is how and why these tools are used. So how do data miners apply these techniques, and to what end?