When beginners get started with machine learning, the inevitable question is “what are the prerequisites? What do I need to know to get started?”
And once they start researching, beginners frequently find well-intentioned but disheartening advice, like the following:
You need to master math. You need all of the following:
– Calculus
– Differential equations
– Mathematical statistics
– Optimization
– Algorithm analysis
– and
– and
– and ……..
A list like this is enough to intimidate anyone but a person with an advanced math degree.
It’s unfortunate, because I think a lot of beginners lose heart and are scared away by this advice.
If you’re intimidated by the math, I have some good news for you: in order to get started building machine learning models (as opposed to doing machine learning theory), you need less math background than you think (and almost certainly less math than you’ve been told that you need). If you’re interested in being a machine learning practitioner, you don’t need a lot of advanced mathematics to get started.
But you’re not entirely off the hook.
There are still prerequisites. In fact, even if you can get by without having a masterful understanding of calculus and linear algebra, there are other prerequisites that you absolutely need to know (thankfully, the real prerequisites are much easier to master).
Math is not the primary prerequisite for machine learning
If you’re a beginner and your goal is to work in industry or business, math is not the primary prerequisite for machine learning. That probably stands in opposition to what you’ve heard in the past, so let me explain.
Most advice on machine learning is from people who learned data science in an academic environment.
Before I go on, I want to emphasize that this is not a jab. Using the term “academic” is not meant to be an insult. People who work in academia frequently build the tools that people in industry use. And through research, they also push the field forward. I admire these people.
However, there are different incentives in an academic environment. Those incentives shape the mindset and work of people in academia differently than the incentives of people who work in industry. Moreover, the incentives shape the training of people entering academia: students in an academic environment are trained to be productive largely as scholars and researchers.
In an academic environment, individuals are rewarded (largely) for producing novel research, and in the context of ML, that truly does require a deep understanding of the mathematics that underlies machine learning and statistics.
In industry though, in most cases, the primary rewards aren’t for innovation and novelty. In industry, you’re rewarded for creating business value. In most cases, particularly at entry levels, this means applying existing, “off the shelf” tools. The critical fact here, is that existing tools almost all take care of the math for you.
“Off the shelf” tools take care of the math for you
Almost all of the common machine learning libraries and tools take care of the hard math for you. This includes R’s caret package as well as Python’s scikit-learn. This means that it’s not absolutely necessary to know linear algebra and calculus to get them to work.
There’s a good quote about this by Andrew Gelman in his highly regarded book on regression:
“Most books define regression in terms of matrix operations. We avoid much of this matrix algebra for the simple reason that it is now done automatically by computers …. [the computations] are important but can be done out of sight of the user.”
Keep in mind that Gelman is a very well regarded statistician. He’s a statistics professor at Columbia University (an Ivy League university) and he’s written several best-in-class books on topics like regression and Bayesian statistics. And while this quote deals specifically with regression, the same principle applies to machine learning, broadly speaking.
This point must be emphasized: modern statistical and machine learning software takes care of much of the mathematics for you.
This means that it’s possible for you to build a good predictive model without almost any knowledge of calculus or linear algebra. If you’re still not convinced of this, then take a careful look at An Introduction to Statistical Learning or Applied Predictive Modeling. These are two excellent books on machine learning (AKA, statistical learning; AKA, model building). There’s almost no calculus or linear algebra in either of them.
This is great news for a beginning data scientist who wants to get started with machine learning. You can call an R function from caret or a function from Python’s scikit-learn and it will take care of all of the mathematics for you. Knowing how all that mathematics works “under the hood” is neither necessary nor sufficient for building predictive models as a beginner.
To be clear, I’m not suggesting that these tools do all the work for you. You still need to be well-practiced at applying them. You need to have a solid understanding of the heuristics, best practices, and rules of thumb associated with making them work well. Again though, much of the knowledge required to make these tools perform well does not require matrix algebra and calculus.
Most data scientists don’t do much math
I think many beginners have an inaccurate image in their minds of what data scientists actually do. They imagine that data scientists spend their days pensively standing at a whiteboard, scribbling math equations between sips of coffee.

That’s just not accurate.
So how much math does a data scientist actually do?
If we’re talking about entry level data scientists to intermediate level data scientists, I’d estimate that they spend less than 5% of their time actually doing mathematics. And quite frankly, 5% is probably a bit generous.
Even if we talk about machine learning only, you’ll still only spend less than 5% of your time doing math. (And quite frankly, most entry-level data scientists won’t spend much of their time on ML.) When you build a model, you will spend very, very little time doing any math.
The reality is that in industry, data scientists just don’t do much higher level math.

But most data scientists do spend a huge amount of their time getting data, cleaning data, and exploring data. This applies both to data science generally, and machine learning specifically; and it particularly applies to beginners.
If you want to get started with machine learning, the real prerequisite skill that you need to learn is data analysis.
The main prerequisite for machine learning is data analysis
For beginning practitioners (i.e., hackers, coders, software engineers, and people working as data scientists in business and industry) you don’t need to know that much calculus, linear algebra, or other college-level math to get things done.
But you absolutely need to to know data analysis.
Data analysis is the first skill you need in order to get things done.
It’s the real prerequisite for getting started with machine learning as a practitioner.
(Note that as this post continues, I’m going to use the term “data analysis” as a shorthand for “getting data, cleaning data, aggregating data, exploring data, and visualizing data.”)
This is particularly true for beginners. Although at high levels there are some data scientists who need deep mathematical skill, at a beginning level – I repeat – you do not need to know calculus and linear algebra in order to build a model that makes accurate predictions.
But it will be nearly impossible to build a model if you don’t have solid skills with data analysis.
Even if you use “off the shelf” tools like R’s caret and Python’s scikit-learn – tools that do much of the hard math for you – you won’t be able to make these tools work without a solid understanding of exploratory data analysis and data visualization. In order to properly apply tools like caret and scikit-learn, you’ll need to be able to gather, prepare, and explore your data. You a need solid understanding of data analysis.
80% of your work will be data preparation, EDA, and visualization
It’s common knowledge among data scientists that “80% of your work will be data preparation.” This is true, although I want to clarify what this means. When people say that “80% of your work will be data preparation” that’s sort of a shorthand way of saying “80% of your work will be getting data (from databases, spreadsheets, flat-files), performing exploratory data analysis, reshaping data, visualizing data to find insights, and using EDA.”
While this figure is about data science in general, it also applies to machine learning specifically: when you’re building machine learning models, 80% of your time will be spent getting data, exploring it, cleaning it, and analyzing results (using data visualization).
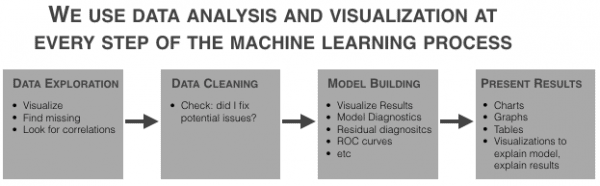
To be a little more blunt about it, if you don’t know calculus and linear algebra, you can still build useful models, but if you aren’t really proficient with data analysis, you’re screwed.
For beginning practitioners, data hacking beats math
This isn’t just a glib statement. Many, if not most of the best data scientists and model-builders I know at several Fortune 500 companies aren’t particularly masterful at calculus, linear algebra or advanced math. But they are exceptional at data analysis.
Here’s a personal example: one of the best predictive modelers I’ve worked with knows very little advanced math.
To be clear, she has a PhD, but her PhD is in Social Psychology. She didn’t receive training in any serious math. Based on working with her and talking with her for several years, I’m confident that her knowledge of calculus and linear algebra was very, very limited.
But, she definitely knew her way around a dataset. She knew how to explore and prepare a dataset to make machine learning algorithms work in a practical setting.
To be fair, any person with a PhD in machine learning would have smoked her when it came to explaining the underlying mathematics. She would have withered under questioning about the deep mathematical underpinnings of k-means or support vector machines. But, those things weren’t her strengths. She was a true practitioner, and she was paid quite handsomely, because she made accurate predictions. No one gave a damn about her math chops. She got results, and clients paid.
I want to emphasize that this particular friend isn’t a unicorn. I know dozens of people like this (she’s just a good example). Moreover, these practitioners aren’t employed at a “low end” companies. They all work at places like Apple and other top-tier Fortune 500 companies; companies that are crushing their goals and generating huge profits. These people are solid employees at excellent companies.
Math is important, but not for entry level practitioners
Even as I write this, I’m imagining the hate-mail and condemnations from the people who would insist that you that you need lots of math.
So before I overstate my case, and potentially alienate a large group of people that I respect and admire, let me be clear: math is important. And in particular, there are some circumstances where math is very important.
First of all, math is particularly important if you’re doing machine learning research in an academic setting.
Second, in industry, math is also important for a small subset of more advanced data scientists. There are people in industry at high levels who are also using advanced math on a regular basis. In particular, there are people at companies like Google and Facebook who are pushing the boundaries of machine learning – people working on bleeding edge tools. These people almost certainly employ calculus, linear algebra, and more advanced math routinely in their work.
But in this article, I’m not talking about senior level data scientists working on cutting edge tools. And I’m not talking about academic work (as much as I admire academics and theorists for developing the techniques that we use on a daily basis).
I’m talking about entry level data scientists. I’m talking about people who are just getting started and trying to find a path at the very beginning stages.
Beginners do need some math for machine learning
I’ll also clarify and say that even for the beginners that I’m addressing in this article, you do need some math.
I’ll write my full advice in another blog post, but I’ll briefly summarize it here: to get started learning practical machine learning, an entry level data scientist needs to have basic comfort working with numbers, calculating percentages, etc. You need at least as much math skill as a college freshman at a good university. You’ll also need knowledge of basic statistics … about as much knowledge as you’d get in a basic “Introduction to Statistics” course. That is, you need to understand concepts like mean, standard deviation, variance, and other things you’d learn in an intro stats class.
However, when people tell you that you absolutely need to know calculus, differential equations, optimization theory, linear algebra, and more just to get started building machine learning models, this is flat out wrong.
Your first milestone: master data analysis
What does this mean for you, the beginning data scientist?
The take-away here is that for beginning data scientists and ML practitioners, data expertise beats math expertise. You’ll get much farther if you really know your way around a dataset, than if you know calculus and college-level math.
So if your goal is to get a job in business or industry, your first milestone is mastering data analysis.
It’s not mastering calculus.
It’s not being able to write proofs or grind through math problems.
It’s data analysis.
You need to master how to gather data, explore it, and prepare it. This means that you need to master data visualization and data wrangling (including aggregation). Then you need to be able to use data visualization and data wrangling together to be able to perform exploratory data analysis.
If you’re working in R, then I recommend that you learn the following:
– ggplot2 for data visualization, including basic visualizations like scatterplots, histograms, bar charts
– dplyr for aggregating and reshaping a dataset
– Learn how to use ggplot and dplyr together for exploratory data analysis
If you’re working in Python, learn the following:
– Base python
– Pandas, for aggregating and reshaping your data
– Matplotlib for data visualization. In particular, learn pyplot for basic visualizations, and use Seaborn for more advanced statistical graphics
– Learn to use Pandas and data visualizations together for exploratory data analysis.
If you’re a beginner, and you want to get started with machine learning, you can get by without knowing calculus and linear algebra, but you absolutely can’t get by without data analysis.
If you master data analysis, you’ll be well prepared to start building machine learning models that work.
A very detailed and nice guide for beginners. I am stuck at regression currently.
This article is very inspiring. I am motivated on where to focus more of my attention. Thank you very much!
Thank you. This article is genuinely a motivation for the people like us who looks for someone to guide them. Thank you again
You’re welcome.
Thanks for writing this post! It came at a perfect time, when I was starting to feel dejected about being able to move forward with a career in Data Science, unless I went back to school to learn all subjects of math, and ignoring my passion of data exploration and visualization. The post has relight the fire to pursue Data Science! Thank you for the dose of reality and practicality.
Agreed, great post! Some brief background, then a question: I am an aspiring data scientist, but don’t have a rigorously quantitative background (BS and MS degree in finance). I’ve been working for a large investment firm for the past 4 years and, during the most recent 3 months, have be been learning R on my spare time. Knowing this much about my situation, what types of roles can I realistically expect to be considered for in data science/business intelligence/etc.? Apologies if this topic has already been addressed in a previous post. Thank you in advance for your thoughts!
This post is very encouraging for me, I started to self-studying Data Analysis 3 years ago just for fun and in my free time. I’m an engineer and I’m trying to change my career path to Data Science, but sometimes the ‘real’ Data Scientists could be very protective of their profession and tend to diminish the self-taught guys like me.
I do understand some math but sometimes the math used in ML could be very hard to grasp and I got frustrated, reading some information or books on the subject could be very challenging. Anyway this post gives me some light in my objective of starting my consulting. Thanks!
Now if I could only find those “beginner” data scientist jobs being alluded to…
That’s the problem. There’s really none out there until you build an extensive portfolio of your work on Github. Trust me on this if you want employment get an MS in Data Science. Even if you use 5% of the theory in your job…IT’S THE THEORY THAT HELPS YOU GRADUATE WHICH LANDS YOU THE JOB!!! Don’t get fooled about stories about people picking data science without formal training. They were previously in fields that required math and statistics which is what you need and looks great on a resume. Take it from a person who gave the above a shot. Save the stress, the constant grind of going at it all by yourself (can you learn this by yourself…absolutely… but not having a support network or peer group to work with is not healthy.) and the heartache…GET THE DIPLOMA! Even if you do land a job. You’re gonna do all that work just to get an entry junior level wage because you don’t have the diploma. From an ROI standpoint it’s not worth it.
Just my two cents from someone who’s been through the the grind.
Awesome…thanks for sharing..
You make a very important point, but for me this article is so very verbose! I got frustrated after a while and only skimmed, so take my comment with a grain of salt.
reading is hard
LOL
Thanks for this post. So, at what point does the math become necessary and if so, what kind of math learning do you recommend?
Your observations are brilliant and on-target. Throughout my engineering career I’ve found the acquisition and conditioning of the data to be the first major challenge. Doing regressions on that data is a relatively minor aspect of the work. The second major challenge is presenting my results visually to an audience of managers of varying technical abilities.
What are good courses to take in Data Analytics?
Thank you SO MUCH for this! My ultimate goal is to be a machine learning practitioner but was getting frustrated trying to work my way through Linear Algebra while also wondering if I should start with data analysis first. Now I know where to start! Thanks again!
Awesome. Happy to help.
For the time being, focus on analysis. Use that as a platform to dive into basic ML.
Then, when you’re ready to get to the bleeding edge (deep learning, etc) you can backfill your knowledge of linear algebra.
Awesome post. I’d like to add an analogy from trading financial derivatives:
One of the major breakthroughs in order to price options (financial derivatives) is the Black & Scholes model. It’s based on partial differential equation.
Now if you want to modify the formula, improve it or edit it, you need calculus (similar to a ML engineer who builds an algo from scratch).
But, in order to use the Black & Sholes model so that you can trade options, you simply put in numbers. My nine year old daughter could do it.
My conclusion: if you want to be able to write an algo from scratch, you need a very high math level. If you want to use algos, you don’t need math. You need to understand how it behaves.
Hope that helps
“Now if you want to modify the formula, improve it or edit it, you need calculus (similar to a ML engineer who builds an algo from scratch) … But ….”
Exactly. ML is a lot like this. To be clear, there are still a lot of little thing you need to know to make the tools work properly, but at the beginning stages, calculus isn’t among them.
Exactly … this example makes sense.
I recently read that advanced math was required to learn ML and while i was moping around looking for a ray of hope, i found this article. Thanks!! At least i have some direction now.
You’re welcome.
In the long run, advanced math can be helpful, but in the short-term, focus on a data-visualization/data-manipulation stack in R or Python.
So, depending on which programming language you use, I recommend the following packages to learn visualization/wrangling/analysis:
R: ggplot2, dplyr, tidyr, stringr
Python: numpy, pandas, matplotlib, seaborn
After those, you can move on the the respective machine learning package for your language.
Thanks a lot for the nice article. This blog post helped me to choose my elective.
What does a Calculus refers to?
integral calculus or differential calculus??
Both
Thank you for this post. It was a relief to know that learning to manipulate data is more important that the math underlying the algorithm.
However, there is going to be a point of time when I would have to learn some math too. So in the article above, you said you would reserve talking about the maths needed for machine learning in another blog post. Is the blog post out? If not, can you give us an idea of the math needed for machine learning?
Thank you so much!
I haven’t published that yet.
For starters, learn a little bit about random variables (probability), some very, very basic statistics (means, medians, variance, standard deviation), and summation notation.
If you know these basics, you should know enough to approach the book Introduction to Statistical Learning (ISL).
ISL essentially requires no calculus or linear algebra. If you study ISL, you’ll learn a ton about machine learning. Again, it only requires basic stats and a little probability.
This is ninja blog post, thank you very much. I wanted to ask ,since i have used calculus and linear algebra in graduation but i am not aware how these things are applied in ML context.I work mainly on web related stuff and recently i learn python (django).I also like data visualization (D3) and loving matplotlib. I think i am fairly comfortable with calculus and linear algebra.Could you please publish another blog post or may be two for intermediate and advance ML(trilogy).
Hi,
Just my 2 cents as well.
I am a MSc Business Analytics student at top European University, where the entire focus of the program is to become a Data Scientist or Researcher for those interested. While we do study ML, along with the underlying mathematics spanning algebra,geometry,statistics, etc….. I have to say I have no background whatsoever in programming or mathematics or statistics. Literary null!
Yet so far I have been more then able to grasp the knowledge, understand and apply it. Yes, I did have to read quite a bit, practice a lot and watch a lot of videos explaining algorithms and the maths associated, but considering I have zero quantitative background and programming background, suggests it is not the most heavy math fields.
Most important point is – be curious, analytical and also dedicated in terms of allowing enough time for concepts to sink in and do a lot of reading/practice on your own time and pace ! Just stay motivated and keep practicing and trying. With time and repetition knowledge suddenly grows and hard concepts become clear as day.
Regards,
Pav
Well put!!!!
What all maths do senior data scientists work with? Can you write a blog about it?
Thank you very much for the explanation. It is very much helpful for me to decide studying ML.
I am not seeking a job but i am a contract worker started to understand the importance of ML and wanted to implement ML in my local projects.
Not sure where to start …
had a few tries with MIT opencourseware by Gilbert’s lecture series, linear regression from khan academy, EDX, coursera, other online sources but not so successful
Pls do recommend where to start if possible….
Have you mastered foundational data science yet? Data visualization, data manipulation, and data analysis?
You haven’t mentioned anything about your current knowledge, background, and skill set.
If you provide more info, I can direct you in a more specific way.
This might be a bit off-topic, but I wanted to know, if I wanted to start building ML projects using supervised and unsupervised learning, then do I need a graphics heavy computer?
Very nice information. Can you upload an article which explained a detail approach of data analysis.what are the components we looked for data analysis .Please upload an article regarding Basic data analysis to perform.
It’s very useful for me and now I am clear about what I want to do.
????
Owsm
It was Nice and deeply explaination
Thanks
Explanation was all on point.
Many thanks, Vaishali
Nicely explained, easy to understand.
Thanks
Why Python and Not c++
Python is much easier to learn and use and is an industry standard for ML.
C++ is used in some contexts, but typically for more advanced use cases. Furthermore, C++ is somewhat likely to be replaced by Mojo for ML projects.
Learn Python first, and then if you absolutely need it, think about learning C++.
Thanks